Generation vs. Reconstruction: Striking A Balance

Intro
This week at OWL we've been refinining our secondary models to push the next iteration of our audio video world model (AVWM) to its limits! The three pain points last week were a lack of spatial coherence in the visuals, poor spatial coherence in the visuals, low audio fidelity, and a lack of KV caching. We are still working on implementing self forcing to solve the final issue, but we've made good progress on the first two!
TLDR
GANs on VAEs with small latents spoil the latents. Train encoder beforehand then pretend your decoder is a generator. ControlNet makes photorealistic data. Temporal consistency is needed. Depth maps are cool.
The Goal
We need an autoencoder that can decode 4x4 latents into 360x640 (and eventually 720p) images at 60fps. Naturally, much of the information in the images cannot make its way down into the latents. We are ok with losing information in the latent so long as we can get it back later. With MSE+LPIPS only, this does not happen, and the high frequency bands are cut off, resulting in blurry reconstructions:

Getting high frequency details through the latent is essentially impossible at high compression ratios. On top of this, we need our latent to be as much like a spatial downsample as possible (See our previous blog post for why). These constraints are tight... so how do we do it?
People Still Use GANs?
For those who are not in the know on diffusion models, GANs might seem dead. Now everyone uses diffusion and autoregression, right? In reality, GANs are still a crucial building block for the modern autoencoder. We explain the motivation behind this in our autoencoder blog post. However, there are some quirks that come with using a GAN signal in your autoencoder. When you introduce the adversarial term, your autoencoder breaks apart into two separate tasks:
1. Downsample the original image into a latent that is informative enough to reconstruct as much of the original image as possible.
2. Use the original image to make a "code" that can be used by a generator to generate an image that fools the discriminator.
The Rec-Gen Tradeoff
Thus comes the reconstruction-generation tradeoff. For clarity, in the literature this is often used to specify the tradeoff between the autoencoder and the downstream generative model (i.e. diffusion model or autoregressive model). We use it to refer to the autoencoder balancing between being a generator and a reconstructor. In a VAE-GAN, the latent now serves two purposes as we stated earlier. On one hand, it is a downsampled version of the original image, on the other hand it is a code to be used to instruct the decoder on what it should generate. Adversarial weight can directly tune this trade-off, but interestingly enough we have found that the compression factor also indirectly effects it. This makes sense: smaller latents lead to worse reconstructions, which are easier for the discriminator to detect, requiring a stronger generator to actually trick the discriminator. Refer to the following diagram:

Firstly, as the latent size goes down, the bands of frequency that can be recovered from the latent shrinks, and as a consequence, those frequencies need to instead be generated in order to fool the discriminator. As more and more of the content must be generated, the amount of bandwidth the latent uses for reconstruction (i.e. the "image-like" part) shrinks, while the amount of bandwidth used for generation (i.e. a "code" saying what to generate) goes up. For a VQ-GAN, this is totally fine because the VQ codes are... well... codes. As such this kind of semantic compression actually improves the downstream autoregressive model. However, we've consistently found for diffusion that image-like latents are the best, and deviation from this always introduces problems. In this context, we want to avoid any generative information sneaking into the latent.
How Do We Get Around This?
Our simple solution is to just decouple generative and reconstructive training. We train the encoder-decoder end-to-end with only reconstructive losses, then freeze+compile the encoder to focus on post-training with the decoder. This has several benefits:
- Without a discriminator, we have a much faster training speed on stage 1
- The latents are fully baked after stage 1, so we can train a WM before even having to worry about stage 2, as it's now just decoder post-training
- Distilling the encoder or the decoder is simple and decoupled from actual autoencoder training
- We can run a variety of experiments for better generative decoders while using the same encoder and latent "api"
- Decoder post-training is much faster when skipping the encoder training
Our initial experiments with a GAN decoder did not go super well for small latents. Stability was fine, as we used R1 and R2 penalties from R3GAN, but generations just didn't look right:

It's not bad enough for GANs to be a dead end by any means, but we wanted to explore alternatives due to some other problems we found.
ResNets are Laggy
On Monday we setup a latency evaluation script in our AVWM training repository. When testing a 1B model with fullgraph compilation on a 5090, we were hitting 350 FPS (assuming KV caching and 1 step generation). However, the image decoder was throttling this bigtime as it was capping out around 50 FPS. This is of course unacceptable for our 60fps target. By dropping all normalization layers (replaced with weightnorms) and the middle block of the autoencoder, we posted performance by a factor of about 1.5x without losing any quality, but it still wasn't ideal. It seemed that convolutions at high resolutions add signifigant overhead.
If it was this bad at 360p, 720p was going to be unattainable. As such, we wanted to explore alternate architectures. So then: what if our decoder was a diffusion transformer?
Diffusionception
Why diffuse once when you can diffuse twice? After diffusing a latent, we use it as a conditioning signal to diffuse a full RGB image. There is some literature on this, but we felt it seemed too good to be true. Nevertheless, we pressed onwards. At first we introduced a few too many variables. We assumed that
- Since the latent is another "modality" compared to the RGB images, it should be processed separately: we used the MMDiT architecture
- Since mode collapse is entirely fine and every latent should map to a single image anyways, shortcut objective is fine
- Diffusion needs CFG right? We used latent = random noise as a null embedding (which in hindsight doens't really make sense)
- We can just diffuse in RGB space... right?
- Our learned landscape-to-square worked for ResNets, so maybe we can just put it at the start and end of our DiT?
The resulting samples were quite bad, even though it seemed like the model was learning... something:

Upon further discussions with members of our discord community, we removed CFG and trimmed away the MMDiT architecture. This halfed computation during the shortcut step and halfed the model size, without really influencing performance in any regard. Even so, the images remained weird and noisy as you can see above. As a further simplifiying step, we took a page from our failed proxy decoder experiment and attempted to decode not an RGB image, but a Flux Latent. We imagined going from a 4x4 latent to a 64x64 latent was easier than going to a 360x640 RGB image. Initial samples look better but... weird:

We had cut out everything else, we realized it was time to part ways with our beloved aspect ratio convolutions. We instead just did weird patch sizes (p = (5,2) resulting in 360 total tokens). Since we no longer had the square image we couldn't do the pixel shuffle used in Flux to push spatial dims into channel dims (i.e. 64x64 c16 to 32x32 c64). Alas, we simply accepted this and moved on. Finally, we were starting to get samples better than the original autoencoder reconstructions!

Diffusion models are slow to train, but even at 90k steps, this model is looking quite solid! We are going to wait until ~200k to get a better sense of things.
Brief Aside On Audio VAEs
So if you saw our samples from lsat week, the audio quality was not all there. Well on Monday we cleaned up the architecture, removing middle blocks and replacing normalization with weight normalization. The samples we initially got were lossless, and we were over the moon! But... sadly when we went to prep the data for the AVWM, we found that when deleting the middle block we had also deleted the final down/up stage and were only compressing by 105x. This resulted in lossless reconstructions, but the autoencoder was no longer compatible with our AVWM. We added the lost layer back in, and are now retraining an autoencoder that is far beyond our previous iteration, but probably only 90% of the way to being lossless. We believe an adversarial stage will be fine here, as the compression factor of 735x is very small in the realm of audio VAEs.
Temporal Flickering
One problem we have not had the change to solve yet is that of temporal flickering. Consider the case where each frame is decoded independently. This is how our current model functions. When your frames are all reconstructed, there is a smoothness between latents that directly translates to smoothness between the decoded frames. See reconstruction from our previous VAE below:

Now when you add a generative component to the decoder, its decisions on what it's going to generate vary from frame to frame, so even if the latents are similar, the generated result need not be temporally consistent in regard to the generated high frequency details. See below a reconstruction of the same video with DCAE. If you look closely, the generated high frequency details change and “flicker” from frame to frame.
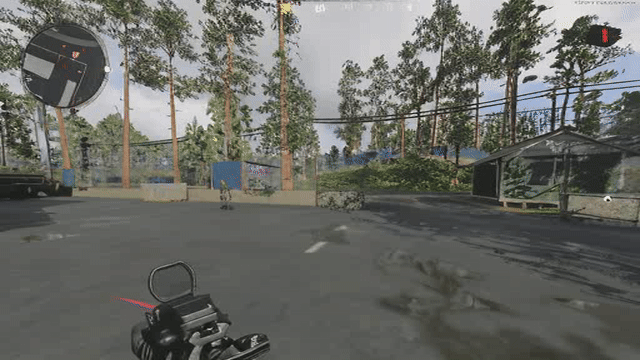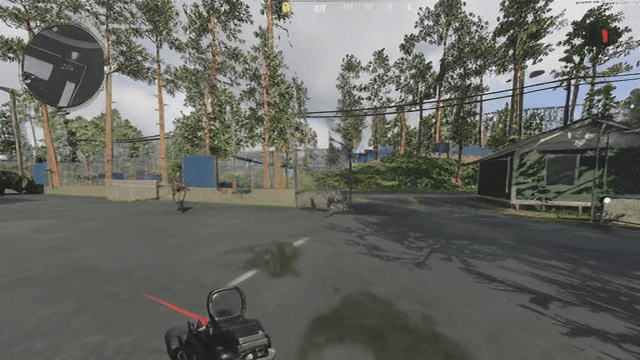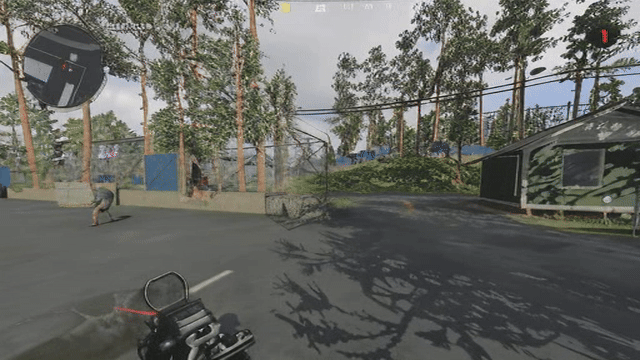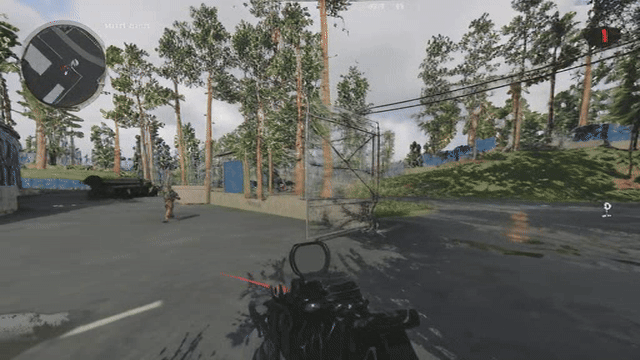
Note that this DCAE instance is f64c128 so it has a 4x higher latent capacity, and is noted in their paper as not being diffusable. We only use it to illustrate GAN induced flickering. See the ground truth below to compare:
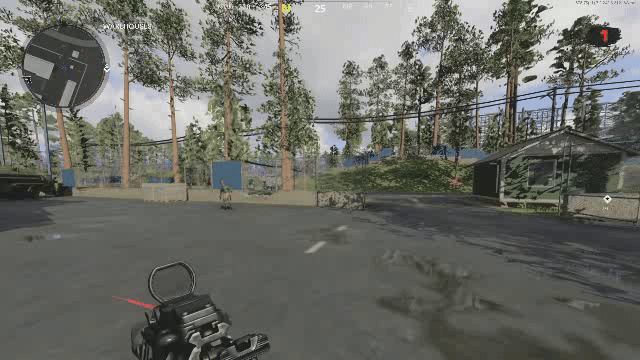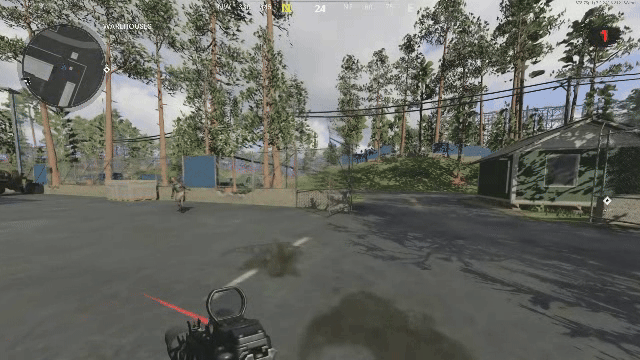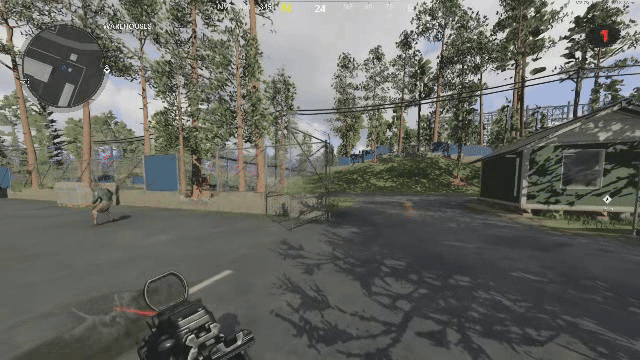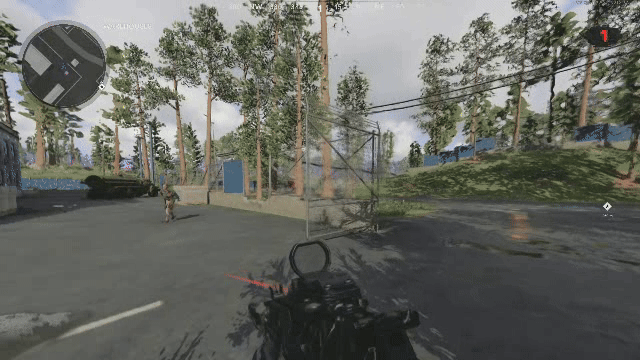
We have a solution involving frame pairs currently in the works, and just prepared the dataset for it today! We will share our results on twitter if the experiment is successful.
The Need For Depth Consistency
One very clear problem in the initial video models of 2024 was that they did not do motion very well. The motion of entities or objects in generated videos did not line up with how those objects actually move in the real world. This was exaggerated for smaller models. VideoJAM largely solved this problem by teaching the model to also diffuse an RGB representation of optical flow. We explored this exact approach a few weeks ago but did not find any success with it, likely because our latents weren’t ideal for it (4x4 flow and 256 channels, ouch). For small world models, we’ve found there’s a weird “tearing” as the camera looks around.
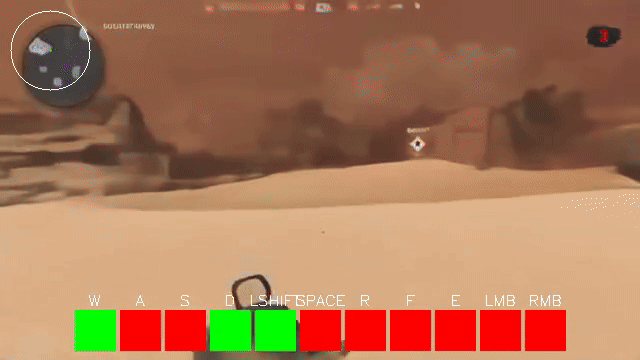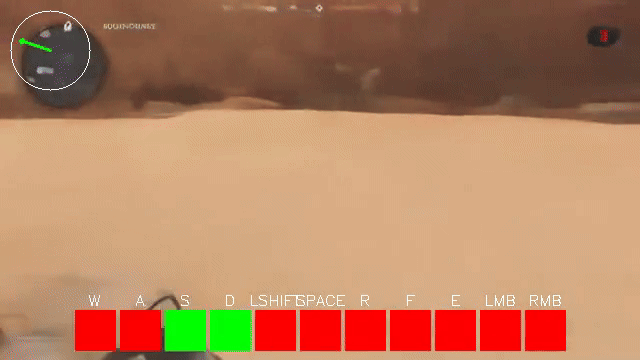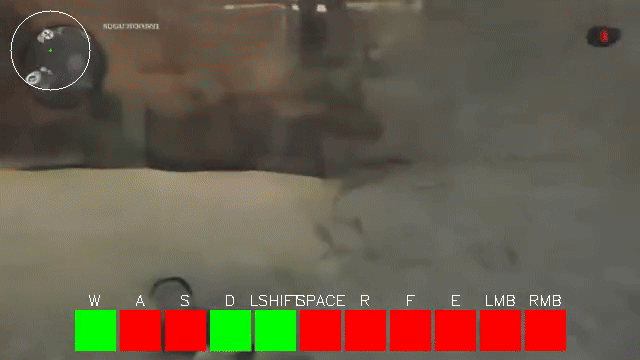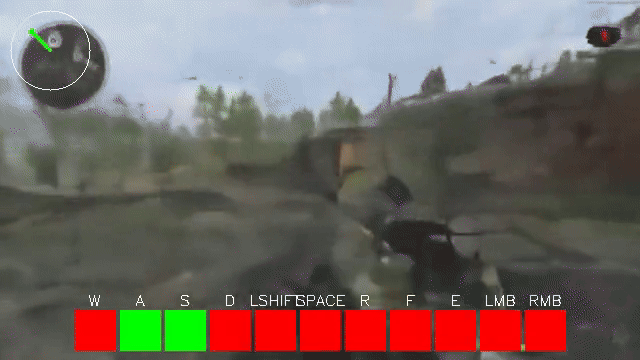
This seems reminiscent of how poorly initialized gaussian splats without depth supervision look. Ahead of doing proper 3D representation, we are experimenting with depth maps passed alongside RGB images in our autoencoders to see if RGB + Depth latents assist the world model in creating more plausible scenes. If this is successful, we were further look into a 7-channel VAE that also compresses optical flow, such that we can train a diffusion world model to generate games with plausible spatial layouts and motion.
Looking Ahead
Self Forcing
We're in the process of implementing and training self-forcing, a method that allows the model to train on its own outputs in order to prevent error accumulation. This will allow us to directly use KV caching when rolling out with the world model.
3D Conditioning
Using pipelines like MegaSAM, we can get coherent depth and point clouds paired with our video data. This allows us to condition the world model on a low fidelity representation of the 3D scene. Since the goal is a conditioning signal, and not high fidelity reconstruction, we are using smaller models with lower quality in order to optimize throughput.
ControlNet
This week we did some experiments with ControlNet for SDXL to see how we can augment existing game data. This was an overwhelming success, and we now believe that ControlNets can be used for Game->Photorealistic style transfer to allow for us to train photorealistic world models on non-photorealistic games. See some of the samples below for conversions we did on our CoD zombies dataset:



We are actively looking for anyone with ControlNet expertise to push this to its limits! So if you are a ControlNet wizard, please reach out. The 3 big problems to solve will be
- Temporal coherence (We will probably need to do video ControlNets)
- Higher Throughput (Diffusion distillation and inference engines)
- Automated prompt generation (Multiple styles for the same games)
Join our server! We have over 300 active members, and nearly a dozen unique contributors to our GitHub repositories. Engage with the industry’s top researchers.
We’re actively hiring. You can apply here. We provide competitive packages and all of our employees work on some of the coolest open source projects around.